Post jest kontynuacją 1-szej części serii.
W dzisiejszym wpisie, zajmiemy się tematem przeszukiwania wektorowych baz danych. Z racji że zależy nam też na tym, aby nie zamykać się na konkretną firmę, dopiszemy funkcjonalność przełączania się między danymi dostawcami.
Obsługa wielu dostawców modeli AI
W naszym przypadku zastosujemy wzorzec adapter, dzięki czemu będziemy mogli bez większych zmian kodu źródłowego, przełączać się między modelami dostarczanymi od OpenAI oraz Ollamy.
Zacznijmy od zdefiniowania dwóch funkcji, (które w zależności od wybranego modelu) zwrócą nam właściwą wersję metody search. Posłuży ona później do komunikacji, a tym samym do przesłania naszego zapytania dla dostawcy usługi.
def openai_searcher(model_name: str) -> Callable[[str], str]:
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def search(prompt: str) -> str:
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Jesteś pomocnym asystentem."},
{"role": "user", "content": prompt},
],
)
return response.choices[0].message.content
return search
def ollama_searcher(model_name: str) -> Callable[[str], str]:
def search(prompt: str) -> str:
url = "http://localhost:11434/api/chat"
payload = {
"model": model_name,
"messages": [
{"role": "system", "content": "Jesteś pomocnym asystentem."},
{"role": "user", "content": prompt},
],
"stream": False,
}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["message"]["content"]
except requests.exceptions.RequestException as e:
return f"[Błąd połączenia z Ollama]: {str(e)}"
return search
Przy czym wybranie odpowiedniego wywołania, będzie zależało od przesłanego parametru dla funkcji choose_llm która będzie ładowała powyższe adaptery.
def choose_llm(search_provider: str, search_model: str) -> Callable[[str], str]:
if search_provider == "openai":
return openai_searcher(search_model)
elif search_provider == "local":
return ollama_searcher(search_model)
else:
raise ValueError(f"Nieobsługiwany provider: {search_provider}")
Teraz czas zebranie naszego promptu i przesłanie do funkcji choose_llm, którą wcześniej zdefiniowaliśmy.
def search(user_query, results , search_provider, search_model):
retrieved_docs = results["documents"][0]
context = "\n".join(retrieved_docs)
prompt = f"""
Odpowiedz na pytanie użytkownika na podstawie kontekstu.
Kontekst:
{context}
Pytanie:
{user_query}
"""
ask_llm = choose_llm(search_provider, search_model)
response = ask_llm(prompt.strip())
return response
Pozostałe funkcje zostały opisane w 1 części (Import danych).
Finalny kod:
import json
import os
from typing import Callable, List
import requests
from chromadb import PersistentClient
from dotenv import load_dotenv
from openai import OpenAI
from rich.console import Console
from rich.panel import Panel
from rich.table import Table
from sentence_transformers import SentenceTransformer
load_dotenv()
console = Console()
def chunk_text(text: str, chunk_size: int = 500, overlap: int = 50) -> List[str]:
"""
Dzieli tekst na mniejsze fragmenty z określonym rozmiarem i nakładką.
Args:
text (str): Tekst do podziału.
chunk_size (int): Maksymalna długość pojedynczego fragmentu.
overlap (int): Liczba znaków nakładających się między fragmentami.
Returns:
List[str]: Lista fragmentów tekstu.
Raises:
ValueError: Jeśli chunk_size <= 0 lub overlap >= chunk_size.
"""
if chunk_size <= 0:
raise ValueError("chunk_size must be > 0")
if overlap < 0 or overlap >= chunk_size:
raise ValueError("overlap must be >= 0 and smaller than chunk_size")
chunks: List[str] = []
step = chunk_size - overlap
start = 0
while start < len(text):
end = start + chunk_size
if end >= len(text):
chunk = text[-chunk_size:]
chunks.append(chunk)
break
chunks.append(text[start:end])
start += step
return chunks
def get_openai_embeddings(texts: List[str], model_name: str) -> List[List[float]]:
"""
Pobiera embeddingi dla listy tekstów przy użyciu OpenAI API.
Args:
texts (List[str]): Lista tekstów.
model_name (str): Nazwa modelu embeddingów OpenAI.
Returns:
List[List[float]]: Lista embeddingów dla każdego tekstu.
"""
def get_openai_embeddings(texts: List[str], model_name: str) -> List[List[float]]:
"""
Pobiera embeddingi dla listy tekstów przy użyciu OpenAI API.
Args:
texts (List[str]): Lista tekstów.
model_name (str): Nazwa modelu embeddingów OpenAI.
Returns:
List[List[float]]: Lista embeddingów dla każdego tekstu.
"""
try:
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
response = openai_client.embeddings.create(input=texts, model=model_name)
return [r.embedding for r in response.data]
except ValueError as e:
print(f"ValueError przy pobieraniu embeddingów OpenAI: {e}")
except TypeError as e:
print(f"TypeError przy pobieraniu embeddingów OpenAI: {e}")
except ConnectionError as e:
print(f"Błąd połączenia z OpenAI: {e}")
except TimeoutError as e:
print(f"Timeout przy połączeniu z OpenAI: {e}")
except Exception as e:
print(f"Inny błąd przy pobieraniu embeddingów OpenAI: {e}")
return []
def get_local_embeddings(texts: List[str], model_name: str) -> List[List[float]]:
"""
Pobiera embeddingi dla listy tekstów przy użyciu lokalnego modelu SentenceTransformer.
Args:
texts (List[str]): Lista tekstów.
model_name (str): Nazwa modelu SentenceTransformer.
Returns:
List[List[float]]: Lista embeddingów dla każdego tekstu.
"""
try:
model = SentenceTransformer(model_name)
return model.encode(texts, show_progress_bar=False).tolist()
except Exception as e:
print(f"Błąd przy pobieraniu embeddingów lokalnych: {e}")
return []
def embeder_loader(provider: str, model: str) -> Callable[[List[str]], List[List[float]]]:
"""
Tworzy funkcję embedingu na podstawie wybranego providera.
Args:
provider (str): "openai" lub "local".
model (str): Nazwa modelu do użycia.
Returns:
Callable[[List[str]], List[List[float]]]: Funkcja przyjmująca listę tekstów i zwracająca embeddingi.
"""
if provider == "openai":
def embeder(texts: List[str]) -> List[List[float]]:
return get_openai_embeddings(texts, model_name=model)
else:
def embeder(texts: List[str]) -> List[List[float]]:
return get_local_embeddings(texts, model_name=model)
return embeder
def openai_searcher(model_name: str) -> Callable[[str], str]:
"""
Tworzy funkcję zapytującą model OpenAI (Chat Completions API) przy użyciu podanej nazwy modelu.
Args:
model_name (str): Nazwa modelu OpenAI, np. "gpt-4", "gpt-3.5-turbo", itp.
Returns:
Callable[[str], str]: Funkcja, która przyjmuje prompt (str) i zwraca odpowiedź modelu (str).
"""
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def search(prompt: str) -> str:
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Jesteś pomocnym asystentem."},
{"role": "user", "content": prompt},
],
)
return response.choices[0].message.content
return search
def ollama_searcher(model_name: str) -> Callable[[str], str]:
"""
Tworzy funkcję zapytującą lokalny serwer Ollama za pomocą wybranego modelu.
Args:
model_name (str): Nazwa modelu dostępnego w Ollama, np. "llama3", "mistral", itp.
Returns:
Callable[[str], str]: Funkcja, która przyjmuje prompt (str) i zwraca odpowiedź modelu (str).
"""
def search(prompt: str) -> str:
url = "http://localhost:11434/api/chat"
payload = {
"model": model_name,
"messages": [
{"role": "system", "content": "Jesteś pomocnym asystentem."},
{"role": "user", "content": prompt},
],
"stream": False,
}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["message"]["content"]
except requests.exceptions.RequestException as e:
return f"[Błąd połączenia z Ollama]: {str(e)}"
return search
def choose_llm(search_provider: str, search_model: str) -> Callable[[str], str]:
if search_provider == "openai":
return openai_searcher(search_model)
elif search_provider == "local":
return ollama_searcher(search_model)
else:
raise ValueError(f"Nieobsługiwany provider: {search_provider}")
def search(user_query, results , search_provider, search_model):
"""
Generuje odpowiedź na podstawie zapytania użytkownika oraz dostarczonego kontekstu.
Args:
user_query (str): Zapytanie użytkownika.
results (dict): Wyniki wyszukiwania zawierające dokumenty w formacie {"documents": [[str, str, ...]]}.
search_provider (str): Dostawca modelu językowego, np. "openai" lub "local".
search_model (str): Nazwa modelu językowego do użycia.
Returns:
str: Wygenerowana odpowiedź na podstawie kontekstu i zapytania użytkownika.
"""
retrieved_docs = results["documents"][0]
context = "\n".join(retrieved_docs)
prompt = f"""
Odpowiedz na pytanie użytkownika na podstawie kontekstu.
Kontekst:
{context}
Pytanie:
{user_query}
"""
table = Table(title="Wynik z bazy wektorowej")
table.add_column("ID", style="cyan", no_wrap=True)
table.add_column("Document", style="magenta")
table.add_column("Distance", style="green")
for ids_row, docs_row, dist_row in zip(
results.get("ids", []),
results.get("documents", []),
results.get("distances", []),
):
for i, d, dist in zip(ids_row, docs_row, dist_row):
doc_preview = (d[:1000] + "...") if len(d) > 1000 else d
table.add_row(i, doc_preview, f"{dist:.2f}")
console.print(table)
console.print(Panel(prompt.strip(), title="Prompt"))
ask_llm = choose_llm(search_provider, search_model)
response = ask_llm(prompt.strip())
return response
if __name__ == "__main__":
question= "Czym jest chroma?"
embeder_provider = "local" # openai | local
embeder_model = "all-MiniLM-L6-v2" # all-MiniLM-L6-v2 | text-embedding-3-small
search_provider = "local" # openai | local
search_model = "llama3" # llama3| gpt-4o-mini
try:
# Inicjalizacja klienta bazy danych
client = PersistentClient(path="chroma-db")
collection = client.get_or_create_collection(name="documents")
except Exception as e:
print(f"Błąd inicjalizacji Chroma: {e}")
exit(1)
embed_fn = embeder_loader(embeder_provider, embeder_model)
results = collection.query(
query_embeddings=embed_fn([question]), n_results=3
)
if (
results.get("documents")
and results["documents"]
and results["documents"][0]
):
results = search(
question,
results,
search_provider,
search_model,
)
console.print(Panel(results, title="Odpowiedź"))
Po uruchomieniu powyższej funkcji otrzymujemy:
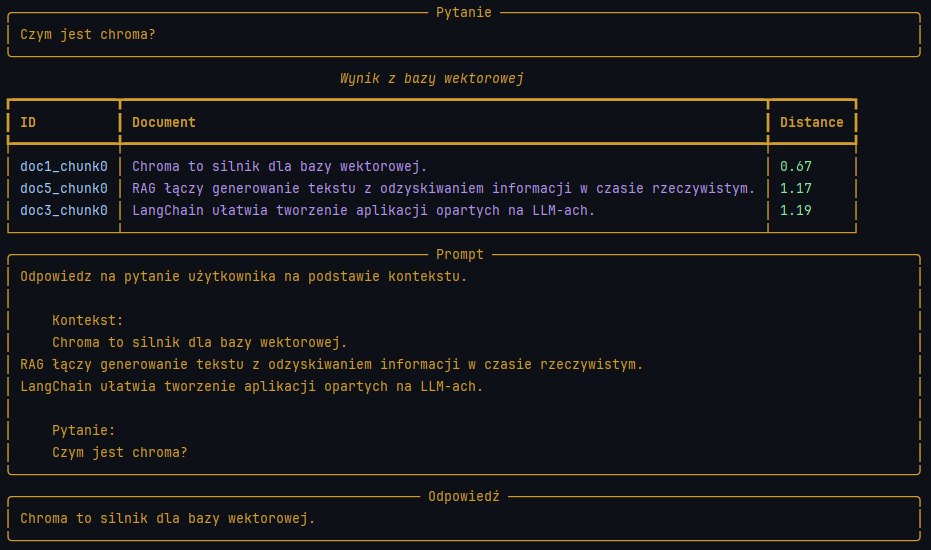
Zwróć uwagę że, odpowiedź, której poszukiwaliśmy miała najkrótszy dystans (3-cia kolumna) od naszego zapytania. W większości przypadków nasza odpowiedź potrafi znaleźć się na 2-gim lub nawet 4-tym miejscu.
Zależy to w głównej mierze od tego:
- na jakich danych został wytrenowany model tworzący embedingi (czy zbiór był wystarczająco duży oraz czy dane był powiązane tematycznie lub ukierunkowane),
- w jakim języku były dane treningowe, (zagraniczne modele mogą sobie gorzej radziś w przypadku analizy naszego rodzimego języka),
- ilości wymiarów którymi operuje nasz model (Wpływa to na to jak wiele cech jest w stanie wyodrębnić i powiązać),
W 3-ciej części, zajmiemy się dodaniem GUI do naszej wyszukiwarki i tym samym otrzymamy już w pełni funkcjonalny i przyjazny dla użytkownika RAG.


Komentarze